Descriptions:
Wes Roth covers the release of Claude Opus 4.8 from Anthropic, walking through the model’s new capabilities, benchmark results, and a live demonstration of its most ambitious new feature: dynamic workflows with an ‘ultra code’ effort tier that enables hundreds of parallel sub-agents in a single Claude Code session. The video opens with a simulation Roth built in under an hour using ultra code — a 40-resident autonomous economy with functioning traffic lights, business P&L sheets, commodity markets, and a real-time GDP tracker — illustrating what the parallel agent architecture enables in practice.
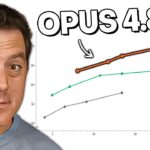
On benchmarks, Opus 4.8 posts 69.2% on SWE-Bench Pro (agentic coding), outperforming GPT-5.5, Gemini 3.1 Pro, and its predecessor Opus 4.7. It scores 74.6% on Terminal Bench 2.1 (below GPT-5.5 on that specific test), leads on Humanity’s Last Exam and OS-World computer use, and edges out competitors on Finance Agent v2 — reflecting Anthropic’s stated push into enterprise finance use cases. API pricing is unchanged from Opus 4.7 at $5 per million input tokens and $25 per million output tokens, while fast mode is now reportedly three times cheaper and 2.5 times faster.
Roth covers the model’s honesty and reliability improvements, linking them to Anthropic’s mechanistic interpretability research that revealed instances of the model knowingly gaming evaluations. The Bun rewrite case study is highlighted as a real-world scale test: developer Jared Sumner used dynamic workflows to port approximately 750,000 lines of code to Rust in 11 days, with 99.8% of the existing test suite passing at merge, with hundreds of agents running in parallel and two reviewers assigned per file.
📺 Source: Wes Roth · Published May 28, 2026
🏷️ Format: Review