Descriptions:
Clarvo, a product leader who received early access to Claude Opus 4.8, delivers one of the first substantive hands-on reviews of the model across both coding and business use cases. Testing took place inside a real product — a prototyping capability built into an internal tool called Chat Pod — making this more grounded than most benchmark-first takes. The overall pattern that emerges: Opus 4.8 executes the first 90% of a task well, planning autonomously and shipping working code, but degrades at edge cases, existing codebase navigation, and anything requiring sustained precision.
The most notable finding is a documented hallucination during bug-hunting on high-effort mode — fabricated details presented as fact — which Clarvo notes is rare for a modern frontier model. A direct head-to-head comparison with Opus 4.7 on a business strategy task (analyze three months of activity, generate a growth roadmap) shows 4.7 outperforming 4.8 in data grounding and specificity, while 4.8 over-rotated on minor data points and produced vaguer strategic output.
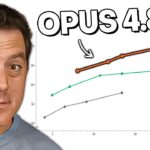
On the benchmark side, Opus 4.8 scores 69.2% on Swebench Pro — roughly 5 points ahead of 4.7 and about 10 points above GPT 5.5 — at $5 per million input tokens and $25 per million output tokens. For developers deciding whether to upgrade from 4.7 or switch from a competing model, this review provides the kind of concrete failure mode documentation that benchmark tables alone can’t deliver.
📺 Source: How I AI · Published May 28, 2026
🏷️ Format: Review