16:30 Foundation Models4 weeks ago SWE-rebench: Lessons from Evaluating Coding Agents — Ibragim Badertdinov, Nebius Ibragim Badertdinov, an AI researcher at Nebius with an unconventional background—a trained dentist turned NeurIPS and ICML author—pr... 0 comments 845 views
23:25 Foundation Models4 weeks ago The Art & Science of Benchmarking Agents — Vincent Chen, Snorkel AI Vincent Chen, research fellow and co-founder at Snorkel AI, took the stage at AI Engineer to share meta-level lessons on what separat... 0 comments 377 views
15:12 Benchmarks1 month ago Can LLMs generate Enterprise Quality Code? — Prasenjit Sarkar, Sonar Prasenjit Sarkar from Sonar presents an enterprise-focused LLM code quality evaluation that goes substantially beyond standard SWE-be... 0 comments 514 views
25:27 Business & Strategy1 month ago The Annual AI Slowdown Panic Is Here The AI Daily Brief examines a new coding benchmark called DeepSWE from a company called Data Curve, which is drawing wide attention f... 0 comments 2.9K views
20:03 Business & Strategy1 month ago Agentic Evaluations at Scale, For Everybody — Nicholas Kang & Michael Aaron, Google DeepMind Nicholas Kang, product manager for Kaggle Benchmarks at Google DeepMind, and Michael Aaron, a Kaggle software engineer, present the c... 0 comments 710 views
39:16 Foundation Models1 month ago Evals for taste: Hill-climbing a slide-generation agent In this workshop from Anthropic's Claude channel, an Anthropic engineer walks through the complete process of designing, building, an... 0 comments 844 views
17:23 Foundation Models1 month ago AI Dev 26 x SF | Andrew Filev: Multi Model Pipelines—How to Get Better AI Results for Less Andrew Filev, CEO of Zenoder, presents findings from his company's in-house applied research lab at AI Dev SF 2026, sharing the resul... 0 comments 53 views
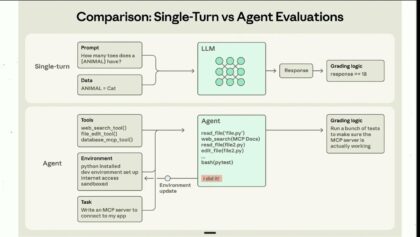
24:37 Foundation Models1 month ago AI Dev 26 x SF | Ara Khan: Evals Are Broken Use Them Anyway Ara Khan, speaking at the AI Dev 26 x SF event hosted by DeepLearningAI, argues that most developers are fundamentally wrong about AI... 0 comments 420 views
31:40 Foundation Models1 month ago Picking the right model Lucas from Anthropicʼs applied AI team delivers a practical framework for selecting the right Claude model in production — addressing... 0 comments 635 views
30:23 Agents & Automation1 month ago AI Dev 26 x SF | Erik Thorelli: Deploying AI Code Review at Scale Erik Thorelli from CodeRabbit presents a detailed, practitioner-level breakdown of what it actually takes to deploy AI-driven code re... 0 comments 103 views